

Cours 2 : Python
CHAPITRE III : MANIPULATION DES DONNEES
- Définition et importation du package
- Pandas est une bibliothèque open source python consacrée à la manipulation des données. Elle fournit des structures de données faciles à manipuler et des outils d’analyse de données assez puissant.
- Elle est basée sur la librairie Numpy.
- Pour utiliser Pandas, il faut l’importer. La syntaxe est : import pandas as pd
- Pour plus d’information sur pandas, consulter la documentation en ligne ou utiliser la fonction help de python : help(pd) après l’importation.
- Pour utiliser une fonction de Pandas, faire : pd.nom_de_la_fontion() après l’importation
- Structures de données
Les structures de données utilisées pour l’analyse sur Python sont les Series et les DataFrames.
- Les Series sont les tableaux de données indexées à une dimension. Pour créer une Series, on utilise la fonction Series() de pandas avec une liste de valeurs en paramètre.
Exemple :
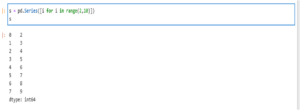
Ici, on a créer la série S grâce à une liste. dtype représente le type de données contenue dans la Serie.
- Les Series
Ici, on a créer la série S grâce à une liste. dtype représente le type de données contenue dans la Serie.
La Serie s est constituée de deux colonnes. La première toujours rangée par ordre croissant indexreprésente la liste des index de la serie. On peut y accéder en faisant nom_de_la_serie.index
La deuxième colonne représente les valeurs. Pour y accéder on peut utiliser l’attribut values des series. On a donc nom_de_la_serie.values
» On peut également créer une Serie à partir d’un dictionnaire. Dans ce cas, les clés deviennent les index.
- Les DataFrames correspondent au format que l’on rencontre généralement en Analyse de données. Deux dimensions dont les variables en colonnes et les individus en ligne.
Pour créer un DataFrame, on se sert de la méthode DataFrame() de pandas à partir d’une liste ou d’un dictionnaire. La syntaxe est : pd.DataFrame(para) où para est un dictionnaire ou une liste.
Exemple : Ici nous avons créer un DataFrame à partir du dictionnaire dico.
Notre DataFrame possède deux variables (height et weight) et 5 individus dont les index vont de 0 à 4.

- Importer des données
- Le DataFrame est la structure de données par excellence pour l’analyse sur python. Sa structure est semblable à un tableur Excel comme nous l’avons vu.
- C’est donc à partir de cette structure que nous allons manipuler les données sur python.
- Dans la pratique, on ne saisie pas les données directement en créant un DataFrame comme nous l’avons vu jusqu’à présent. Plutôt, on les importe avec la structure du DataFrame de Pandas.
Pandas possède plusieurs méthode permettant d’importer des données en fonction du format. Les format les plus répandu sont les formats Excel et csv. Les méthodes associées sont : read_excel() et read_csv() de pandas. Elles prennent en paramètre le chemin d’accès vers le fichier de données à importer.
Exemple : Pour importer la base de données Excel nommée temperature.xlsx et contenu dans le disque D de mon ordinateur, je fais :

Pour un fichier csv, on utilise read_csv() de manière similaire.
- Exporter des données
Il peut nous arriver de vouloir exporter des données une fois certaines transformations faites dans le but de les conserver ou alors de les exploiter sur un autre logiciel. On dit aussi qu’on converti le DataFrame en un fichier csv par exemple
Pour exporter les données sur Python sous format csv, on utilise la fonction to_csv() de Python. On spécifie en paramètre de la fonction le nom de la base et aussi l’emplacement.
Syntaxe : df.to_csv(‘nom_du_fichier.csv’)
Ici, df est le nom du DataFrame que nous voulons exporter et nom_du_fichier, le nom qu’on veut donner au fichier csv.
Par défaut, le fichier exporté conserve les index, pour les supprimer lors de l’exportation, il suffit d’ajouter l’attribut « index = false » à la fonction to_csv().
- Méthodes et attributs de DataFrame
Lorsqu’on importe une base de données pour l’analyse, il y’a un certain nombre de taches basiques que l’on fait pour l’explorer.
- Pour cette partie, on utilisera la base de données « exam_scores.csv » pour nos illustrations.
- Dans notre cas, la base de données est placé dans le répertoire courant. Donc pour l’importer, il suffit de son nom.
- L’attribut shape : Il permet de connaitre les dimensions de notre base de données. Le nombre de variables et le nombre d’individus.
Apres avoir importé la base, il suffit de faire : nom_de_la_base.shape
- L’attribut head/tail : Ils nous permettent respectivement de visualiser les premières / les dernières lignes de notre DataFrame. Elle prennent le nombre de ligne en paramètre; par défaut c’est 5.
Syntaxe : nom_de_la_base.head() ou nom_de_la_base.tail()
- L’attribut info : Il permet de donner un résumé concis de la base de données : Les variables, leurs types, la taille de la base etc.
Syntaxe : nom_de_la_base.info()
- L’attribut describe : Il donne un résumé statistique de la base.
Syntaxe : nom_de_la_base.describe()
- columns/index : donne toutes les colonnes (variables) / les index de la base
Syntaxe : nom_de_la_base.columns
- Indexation et Sélection des observations
Pour sélectionner des lignes ou des colonnes particulière de notre base on utilise loc et iloc.
- Loc est utilisé pour sélectionner les labels alors iloc est utilisé pour sélectionner grâce au index. Pour plus de détail, regarder le fichier pandas.pynb donné avec ce cours.
- Pour sélectionner une variable en particulière, il suffit de faire : nom_base[‘nom_variable’]. Pour sélectionner une ou plusieurs variables, il suffit de passer la liste de variable. On aura donc : nom_base[ [‘var1’, ‘var2’, ‘var3’] ] pour sélectionner uniquement les variables var1, var2 et var3.
- Pour renommer les variables, on utilise rename. On peut également renommer les index.
- Fonctions d’agrégations
L’utilisation de la fonction describe nous donne une description statistique de la base comportant la moyenne, la médiane et le nombre de modalité des variables. Cependant, nous pouvons calculer séparément ces grandeurs grâce aux fonctions mean() pour la moyenne, median() pour la médiane et unique() pour les modalités.
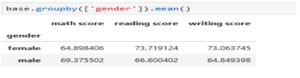
Pour agréger les observations d’une base de données selon les modalités d’une variable, on utilise « groupby ».
Par exemple, on peut vouloir grouper les notes des élèves selon le sexe, on a :
- Les valeurs manquantes
- Les valeurs manquantes sont identifiées « NaN » qui veut dire Not a number. Pour détecter les valeurs manquantes, on utilise les fonctions isnull() ou isna(). On obtient une table de booléens : True si la valeurs est manquante et false sinon.
- Pour obtenir le nombre de valeur manquante par variable, on ajoute l’agrégation .sum()
On a donc : nom.isnull().sum() où nom peut être le nom de la base ou le nom d’une variable.
- Pour imputer les valeurs manquantes, on utilise fillna(). L’imputation peut se faire par la moyenne ou par une valeur précise.
Pour imputer la variable « math score » par la moyenne dans la base exam_score :
inplace permet de modifier dans la base originale.

Merci de ce document
Merci à vous