

Cours 1 : STATA
CHAPITRE II : MANIPULER LES DONNEES
- Les données
Plusieurs commandes sont disponibles pour importer des fichiers de données. Mais pour cette tâche, il est préférable d’utiliser l’interface.
Il suffit donc de cliquer sur « fichier » dans la barre d’outil, puis choisir « import » et choisir le type de données qu’on veut importer. Choisir l’emplacement du fichier en mémoire et spécifier la ligne contenant le nom des variables.
Dans le cas d’un fichier, la commande équivalente est :
import excel « C:\Users\DNelson\Desktop\Cons.xlsx », sheet(« Feuil1 ») firstrow
Firstrow signifie que la première ligne contient les noms des variables.
Une fois les données lues dans Stata, nous pouvons les enregistrer sous format de données data (.dta).
Pour le faire une fois encore, nous privilégions la méthode par clic. Alors cliquer sur l’icone « Data Editor » de la barre d’outil. Une autre fenêtre s’ouvre avec les données importer. Alors il suffit d’aller dans la barre d’outil de cette nouvelle fenêtre cliquer sur « fichier » et sur « save as ». Choisir l’emplacement de sauvegarde et le nom de la base Stata et enfin valider.
Dans le cas d’un fichier Excel importé, la commande d’enregistrement en fichier data est : save « Chemein_d’accès\nom_fichier.dta »
- Quelques éléments du langage
Stata utilise un langage de programmation qui utilise des opérations classiques et des programmes avancés. Cependant, on retrouve à la base de se langages des opérateurs qui permettent de manipuler les nombres et les chaines.
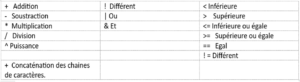
- La sélection des données
Parfois, on a besoin que de certaines observations précises pour nos analyse. Pour les sélectionner et les conserver, on utilise les commandes suivantes :
- if : C’est la clause de condition. Il permet de réaliser un certain nombre d’opérations si certaines conditions sont remplis. Elle réduit notre échantillon en une partie remplissant une condition. Syntaxe : commande if condition
Exemple : list if sexe ==1 : liste les individus pour lesquels sexe = 1
- Drop : Pour supprimer des variables ou des variables de notre base.
Syntaxe : drop nom_variable ou drop n pour supprimer une variable ou l’observation numéro n et drop if condition pour supprimer les observation vérifiant une condition.
- keep : Pour ne garder que les variables spécifiées. Syntaxe : keep var1, var2
- clear : Clear est utilisé pour supprimer les variables en mémoire. C’est l’équivalent de drop_all. On a :
a- clear all : vide entièrement la mémoire.
b- clear ado : Supprime les programmes ado en mémoire.
c- clear programs : Supprime tous les programmes en mémoire.
d- clear results : Supprime les résultats sauvegarder en mémoire.
NB : Avant d’utiliser les commande Keep ou drop, on peut utiliser la commande preserve afin de récupérer par la suite l’échantillon initial.
- Décrire les données
- describe : Donne une description de la base de données active : le nombre d’observations et de variables, la liste des variables, leur type etc.
- codebook : Donne des détails sur les variables en mémoire en spécifiant les données manquantes et quelques statistiques descriptives.
Syntaxe : codebook nom_de_la_variable
- count : On l’utilise généralement avec if pour connaître le nombre d’observation vérifiant une condition. Syntaxe : count if condition. Sans condition, count donne la taille de la base.
- Exemple : count if age >20 donne le nombre de personne de plus de 20 ans.
- Les variables
Stata est un logiciel sensible à la case. C’est-à-dire qu’il fait la différence entre les majuscules et les minuscules.
- Pour créer une variable sous stata, on utilise la commande « generate» ou « gen».
Syntaxe : gen nom_variable = valeur
Exemple gen age = annee_actu – annee_nais permet de créer la variable age.
Recoder les variables
Pour recoder les variables, la commande la plus utilisée est replace.
Syntaxe : replace nom_var = nouvelle_valeur if condition
- Replace zone = 4 if zone == 2 | zone ==3 : Ceci regroupe les modalités 2 et 3 en 4 de la variable zone.
On peut également renommer une variable en utilisant rename.
- Rename var1 var2 : Permet de recoder la variable var1 en var2.
- Les fichiers de données
Trier les données
Pour trier les données, on peut passer par le menu Editor ou en utilisant les commandes. On peut donc utiliser :
- Order / move : permet de trier les variables en mémoire. Aoder réorganise toutes les variables par ordre alphabétique.
Exemple : order sexe age dep va placer les variables sexe, age et dep en début de fichier. L’ordre des autres n’étant pas modifié.
- Sort : permet de trier les observations au sein d’un fichier.
Exemple : sort sexe permet de trier les observations en fonction de la variable sexe
Combiner les fichiers
- Append : Permet d’ajouter des observations à la fin du fichier en mémoire.
Exemple : Si le fichier en mémoire est fichier1.dta et qu’on exécute append using fichier2.dta, on ajoute alors les observations du fichier2 au fichier1.
Pour que ca marche, les variables doivent avoir le même nom dans les 2 bases.
- Merge : Ajoute les variables selon un identifiant des individus commun dans les 2 bases. Il faut que les deux fichiers soient ordonnées selon l’identifiant.
- Exemple : Supposons que dans le fichier1.dta, nous ayons les nom des communes avec leur ID et dans le fichier2.dta, la population des commune avec leur ce même ID. Pour associer à chaque nom de commune la population correspondante :
use fichier2.dta
sort ID
save, replace
use A, clear
sort ID
merge ID using B
Ses un logiciel es intéressant j’aimerais vraiment bien m’améliorer dans sa
Pas de soucis. Nous allons partager plus de ressources dans l’avenir. Merci pour votre intérêt
C’est trop cool le cours, j’aimerais apprendre beaucoup plus…
Nous sommes heureux que ça vous plaise. Merci pour votre intérêt