

Cours 2 : STATA
CHAPITRE III : STATISTIQUE DESCRIPTIVE
- Statistique descriptive unidirectionnelle
Avant toute analyse, il est primordiale de calculer quelques statistiques de base pour les caractéristiques de tendance de nos différentes variables ou groupe de variables.
Pour cela, Stata dispose d’une bonne quantité de commandes élaborées et spécifiques à la nature de la variable d’intérêt.
Nous regrouperons ici ces fonctions en deux grands groupes : Les fonctions relatives aux statistiques descriptives univariées et bivariées.
Description des variables discrètes.
- tabulate : Il permet de réaliser des tableaux de fréquences ou des tableaux croisés sur plusieurs variables. Son abréviation est tab. Ainsi, tab sexe donne un tableau de fréquence sur le sexe alors que tab sexe age donne un tableau croisé entre le sexe et l’age.
- Tab1/tab2 permettent de créer des séries de tableaux de fréquence simple/ croisés sur les variables : tab1 var1 var2 var3 …varn donne n tableaux successifs sur chaque variable et tab2 var1 var2 var3 …varn donne toutes les combinaisons possibles de tableaux croisés entre les variables
- table : Il permet de réaliser des tableaux de fréquence à 3 dimensions. Syntaxe : table var1 var2 var3, row col
- modes permet de calculer rapidement le mode d’une variable.
Syntaxe : modes variable
Description des variables continues.
- summarize : Elle donne un résumé statistique des variables spécifiées. Ce résumé contient la moyenne arithmétique, le nombre d’observations, le maximum, le minimum et l’écart type. La short forme est sum
Syntaxe : summarize var1 var2 var3 … varn ou sum var1 var2 var3 … varn
On peut ajouter l’option détail pour avoir en plus les principaux quantiles.
- table : Elle peut être utiliser afin de calculer certaines statistiques comme la moyenne, la variance, le min, le max, les centiles d’une ou plusieurs variables selon les modalités d’une variable discrète.
Exemple : Si on fait table sexe, c(freq mean chomage), on obtient la durée moyenne de chômage au sein des catégories Homme et Femme.
- tabstat : est pratiquement similaire à table à la différence qu’elle est plus complète car offre plus de statistiques pour chaque catégorie de la variable discrète. Syntaxe : tabstat var_continu by(var_quali) stats(stat1stat2 …statn)
- correlate : Elle donne la matrice de corrélation des variables spécifiées. La forme réduite est corr.
Syntaxe : corr var1 var2 … varn
L’inconvénient de corr est qu’elle n’utilise que le plus grand ensemble d’observations non null pour le calcul des corrélations.
Pour corriger cela, on peut utiliser pwcorr à la place de corr.
Test de normalité d’une variable.
- sktest : Commande pour réaliser des tests de normalité. Elle se base sur les statistiques de Skewness et de Kurtosis. L’hypothèse nulle ici est la distribution normale de la variable aléatoire.
Syntaxe : sktest var1 var2 … varn
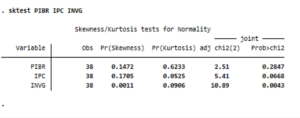
Exemple : Test de normalité des variables INVG, IPC, PIBR
Exemple : Test de normalité des variables INVG, IPC, PIBR
Au seuil de 5%, On accepte l’hypothèse de nulle de normalité pour IPC et PIBR et on rejette cette hypothèse pour INVG.
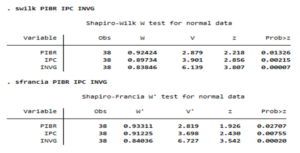
- swilk et sfrancia : Permettent de réaliser respectivement les tests de Shapiro-Wilk et de Shapiro-Francia. L’hypothèse nulle de ces deux tests est la normalité de la variable aléatoire.
En reprenant le même exemple, on arrive au même conclusion pour les deux tests de Shapiro. Au seuil de 5%, on rejette l’hypothèse nulle de normalité des trois variables.
- 1-Statistique descriptive
Quelques tests d’associations
- Test de corrélation : On utilise la commande pwcorr. C’est un test paramétrique qui nécessite la normalité des variables. L’Hypothèse nulle est l’absence de corrélation.
Syntaxe : pwcorr var1 var2 … varn, star(.01) print(.05)
star(.01) signifie qu’on affiche uniquement les coefficients supérieures à 0,01 et print(.05) signifie qu’on met une * (significativité) sur les coefficients significatifs au seuil de 5% .
- Test d’égalité de la moyenne de student : On utilise la commande ttest. C’est un test paramétrique qui nécessite la normalité des variables. L’Hypothèse nulle est l’égalité des moyenne des deux groupes.
Syntaxe : ttest var_continue, by(var_quali)
Ici, var_quali ne doit avoir que deux modalités.
- Test de Chi2 : On utilise la commande tabulate avec en option chi2. C’est un test non paramétrique utilisé pour tester la liaison entre 2 variables qualitatives. L’Hypothèse nulle est l’indépendance entre les deux variables.
Syntaxe : tabulate var1 var2, chi2
La statistique de Pearson donne le seuil à partir du quel on rejette l’hypothèse nulle.
- Test de Krustal et Walis : On utilise la commande ranksum. C’est un test non paramétrique utilisé pour déterminer si k échantillons indépendants sont issus de la même population.
Syntaxe : tabulate var1 var2, chi2
La statistique de Pearson donne le seuil à partir du quel on rejette l’hypothèse nulle.
Les pondérations
Généralement, les enquêtes statistiques sont faites sur des sous échantillons. De ce fait, chaque individus sélectionné à un poids. Le poids d’un individus représente le nombre d’individus de la population que l’individu de l’échantillon représente. Stata autorise 4 types de pondérations :
- fweight : f pour fréquence. Elle utilise un poids qui correspond au nombre de personnes que représente l’individu interrogé. Il doit être un entier.
- pweight : p pour probabilité. Le poids ici correspond à l’inverse de la probabilité d’inclusion de l’observation.
Le cours est très intéressant mais comment faire le le test de sargan ? Quelle est la commande pour le test de sargan.
Cours intéressant
Interressant
Très bien résumé et pratique.
Ras.
J’aimerais approfondir la connaissance en STATA.
Il faut juste continuer à consulter nos publications. Merci
Excellent travail les experts!!!
Merci beaucoup