
cours 1 : langage R et RStudio
Mon premier Script R
Nous pouvons maintenant créer notre premier Script R en suivant la procédure File > New File > R Script ou en utilisant la combinaison clavier Ctrl+Shift+N.
La figure ci-dessous présente quelques commandes R. Les résultats qu’elles sont censées produire sont notés en commentaire. Vous allez sans doute le remarquer, c’est le caractère spécial # qui permet d’insérer un commentaire dans un script R. Par ailleurs, la validation d’une ligne ou d’un ensemble de lignes de commandes se fait en les sélectionnant dans le fichier de Script puis en cliquant sur le bouton Run situé en haut à droite du fichier de Script.
Pour chacune des commande ci-dessous, il est possible de consulter l’aide en tapant la commande : help(« nom de la commande« ). Vous pouvez par la suite nommer et enregistrer votre script dans le répertoire de travail en passant par le Menu File ou en utilisant la combinaison clavier Ctrl+S.
R offre donc la possibilité de réaliser des milliers d’opérations sur les variables de différentes natures ( Nombres, Vecteurs, matrices, chaine de caractères, etc.) en utilisant les commandes associées à ces opérations. La documentation mentionnées ci-dessus est suffisamment riche en la matière. Nous vous laissons donc le soin d’explorer l’univers des commandes de R.
Dans la suite de ce cours, nous allons nous restreindre aux applications statistiques du langage R.
Importation de données et manipulation de variables
L’importation d’un fichier de données sur R se fait à partir du menu « File » de Rstudio. Cependant, selon la nature du fichier à importer, R peut avoir besoin de certaines de ses extensions (Package) pour procéder à l’importation. Nous parlerons de ces extensions un peu plus tard.
Pour le moment, nous allons importer les fichiers de type .csv. Pour illustration, Nous disposons d’un fichier Excel contenant les informations collectées auprès d’une population hôte ayant accueilli les réfugiés d’un pays africains. Il faut donc prendre le soin d’enregistrer ledit fichier au format CSV (séparateur : point virgule) à travers l’onglet « Enregistrer sous » du tableur Excel.
Le chargement du fichier hote.csv se fait à l’aide de la commande read.csv2(), qui permet de lire des fichiers CSV pour lesquels le séparateur de champ est un point-virgule, et le séparateur décimal une virgule. Les données seront associées à l’objet hote à l’aide de l’opérateur d’affectation « <- ». On suppose en effet que l’utilisateur a bien défini le répertoire contenant le fichier hote.csv comme répertoire de travail, soit à l’aide de la commande setwd() soit via le menu « Session » de Rstudio comme nous l’avons mentionné un peu plus haut. Si non, il faudrait indiquer dans la commande read.csv2() le chemin d’accès complet au fichier hote.csv.
Le code hote <- read.csv2(« hote.csv ») devrait importer le fichier de données et créer la variable hote (data frame) dans la fenêtre des objets située en zone Nord-Est de l’écran.
Il est aussi possible que vous receviez un message d’erreur comme celui-ci :
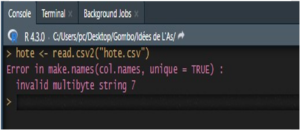
Ceci est sans doute dû à l’encodage du fichier hote.csv (les espaces, les accents et tous autres caractères spéciaux). Une solution consiste à ajouter quelques arguments à la fonction read.csv2 comme suit :
hote <- read.csv2(« hote.csv », fileEncoding = « latin1 », check.names = F).
Le contenu de l’espace de travail peut être visualisé directement depuis le panneau intitulé Environment (Workspace). Si l’on double clique sur le nom d’un data frame, celui-ci est affiché dans un tableau en mode lecture seule.
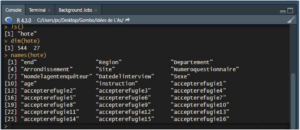
Les données sont généralement représentées sous la forme d’un tableau rectangulaire dans lequel les variables sont arrangées en colonnes, et les observations en lignes. Sous R, on parlera de “data frame”. Une fois que les données sont importées, l’objet hote (le data frame) sera disponible dans l’espace de travail (“Environment”), comme on pourra le vérifier avec la commande ls(). Les dimensions du tableau de données peuvent être vérifiées à l’aide de la commande dim(). La commande names() renvoie le nom des variables.
La commande str() fournit un résumé de l’ensemble des variables avec leur type (int pour les variables numériques, factor pour les variables catégorielles) et un aperçu des 10 premières observations.
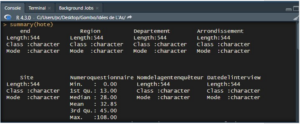
La commande summary() permet de fournir un résumé descriptif univarié pour chaque variable. Dans le cas des variables numériques, R indique les principaux indicateurs de tendance centrale (moyenne et médiane) et de dispersion (étendue, intervalle inter-quartile), ainsi que le nombre de valeurs manquantes représentées par le symbole « NA ».
Vous pouvez produire ces statistiques pour toutes les variables du data frame en appliquant la commande summary(hote) ou en spécifiant une seule variable si vous n’êtes pas intéressé par toutes : summary(hote$age) par exemple.
Nous pouvons retrouver l’âge minimum avec la commande min(hote$age, na.rm = TRUE). L’argument na.rm = TRUE indique à R de ne pas tenir compte des valeurs manquantes. En effet, dans le cas où une variable contient des données manquantes, il faut indiquer explicitement à R ce que l’on souhaite faire des valeurs manquantes. Par défaut, R ne supprime pas les valeurs manquantes, comme on peut le vérifier dans l’aide en ligne (na.rm = FALSE), et se contente de renvoyer la valeur NA pour signaler à l’utilisateur que certaines données sont manquantes.
On peut aussi obtenir l’étendue des valeurs observées avec la fonction range() qui, contrairement à min(), est une commande qui renvoie des résultats multiples (dans ce cas, le minimum et le maximum de la variable age).
range(hote$age, na.rm = TRUE).
La commande unique() permet d’énumérer les valeurs distinctes observées dans une variable. unique(hote$region) permet de connaitre toutes les régions dans lesquelles les hôtes ont été interrogées.
La commande rm() permet de supprimer une ou plusieurs variables de l’espace de travail.
Pour tabuler une variables, on utilise la commande table().
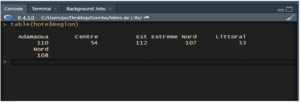
Pour afficher le nombre de valeurs manquantes via la commande table(), il est nécessaire d’ajouter l’option useNA = « always ».
table(hote$Region, useNA = « always »).
On peut plutôt rechercher le nombre d’observations sans donnée manquante avec la commande complete.cases() de la façon suivante : sum(complete.cases(hote$Region))
Recodage de variables
Dans certains cas de figure, on peut être amené à recoder une variable en regroupant certaines valeurs que prend cette dernière. Par exemple, si on veut regrouper les individus en tranche d’âge, il faudra créer une nouvelle variable age2. Pour cela, on utilise la fonction cut().
Celle-ci prend, outre la variable à découper, un certain nombre d’arguments :
- breaks indique soit le nombre de classes souhaité, soit, si on lui fournit un vecteur, les limites des classes,
lorsqu’on spécifie le nombre de classes, R crée des classes de même amplitude.
- labels permet de modifier les noms de modalités attribués aux classes ;
- include.lowest et right influent sur la manière dont les valeurs situées à la frontière des classes seront inclues ou exclues ;
- dig.lab indique le nombre de chiffres après la virgule à conserver dans les noms de modalités.
De façon pratique, j’ai l’habitude d’utiliser la commande range pour connaitre au préalable l’étendu de la variable avant de fournir les limites des classes, puis l’option include.lowest = TRUE permet de ne pas oublier d’inclure l’observation dont l’âge vaut l’âge minimal, puisque par défaut les intervalles ont des bornes ouvertes (c’est-à-dire n’incluant pas) à gauche.
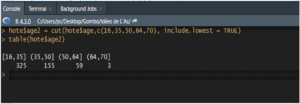
range(hote$age, na.rm = TRUE)
hote$age2 = cut ( hote$age, c(16,35,50,64,70), include.lowest = TRUE)
table( hote$age2 )
Sauvegarde de données
On peut sauvegarder des données au format RData, qui est un format propre au logiciel R. Cela facilite l’archivage de résultats intermédiaires ou l’enregistrement d’un tableau de données nettoyé (recodage de valeurs manquantes ou modalités de variables qualitative, correction des erreurs de saisie, etc.) ou augmenté de variables auxiliaires. Pour cela, on utilisera la commande save(). La commande load() permet quant à elle de recharger des données sauvegardées au format RData. L’extension du ficher peut être indifféremment Rdata ou rda.
save(hote, file = « hote_v1.rda »)
dir(pattern = « rda »)