cours 2 : langage R et RStudio
Indexation de données et graphiques univariés
Packages
L’installation par défaut du logiciel R contient le cœur du programme ainsi qu’un ensemble de fonctions de base fournissant un grand nombre d’outils de traitement de données et d’analyse statistiques.
R étant un logiciel libre, il bénéficie d’une forte communauté d’utilisateurs qui peuvent librement contribuer au développement du logiciel en lui ajoutant des fonctionnalités supplémentaires. Ces contributions prennent la forme d’extensions (packages en anglais) pouvant être installées par l’utilisateur et fournissant alors diverses fonctionnalités supplémentaires.
Il existe un très grand nombre d’extensions (plus de 16 000 à ce jour), qui sont diffusées par un réseau baptisé CRAN (Comprehensive R Archive Network).
La liste de toutes les extensions disponibles sur CRAN est disponible ici : http://cran.r-project.org/web/packages/.
Pour faciliter un peu le repérage des extensions, il existe un ensemble de regroupements thématiques (économétrie, finance, génétique, données spatiales…) baptisés Task views : http://cran.r-project.org/web/views/.
On y trouve notamment une Task view dédiée aux sciences sociales, listant de nombreuses extensions potentiellement utiles pour les analyses statistiques dans ce champ disciplinaire :
http://cran.r project.org/web/views/SocialSciences.html.
On peut aussi citer le site Awesome R (https://github.com/qinwf/awesome-R) qui fournit une liste d’extensions choisies et triées par thématique.
Installation d’un Packages
L’installation d’une extension se fait par la fonction install.packages(), à qui on fournit le nom de l’extension. Par exemple, si on souhaite installer l’extension gtsummary : install.packages(« gtsummary »)
Sous RStudio, on pourra également cliquer sur Install dans l’onglet Packages du quadrant inférieur droit. Alternativement, on pourra avoir recours au package remotes et à sa fonction remotes::install_cran():
remotes::install_cran(« gtsummary »)
Il faut noter que le package remotes n’est pas disponible par défaut sous R et devra donc être installé classiquement avec install.packages(« remotes »). À la différence de install.packages(), remotes::install_cran() vérifie si le package est déjà installé et, si oui, si la version installée est déjà la dernière version, avant de procéder à une installation complète si et seulement si cela est nécessaire.
Chargement d’un Packages
Une fois un package installé (c’est-à-dire que ses fichiers ont eté téléchargés et copiés sur votre ordinateur), ses fonctions et objets ne sont pas directement accessibles. Pour pouvoir les utiliser, il faut, à chaque session de travail, charger le package en mémoire avec la fonction library() ou la fonction require() :
library(gtsummary)
À partir de là, on peut utiliser les fonctions de l’extension, consulter leur page d’aide en ligne, accéder aux jeux de données qu’elle contient, etc.
Alternativement, pour accéder à un objet ou une fonction d’un package sans avoir à le charger en mémoire, on pourra avoir recours à l’opérateur ::. Ainsi, l’écriture p::f() signifie la fonction f() du package p. Cette écriture sera notamment utilisée pour indiquer à quel package appartient telle fonction : remotes::install_cran() indique que la fonction install_cran() provient du packages remotes.
Il est important de bien comprendre la différence entre install.packages() et library(). La première va chercher un package sur internet et l’installe en local sur le disque dur de l’ordinateur. On n’a besoin d’effectuer cette opération qu’une seule fois. La seconde lit les informations de l’extension sur le disque dur et les met à disposition de R. On a besoin de l’exécuter à chaque début de session ou de script.
Mise à jour d’un Packages
Pour mettre à jour l’ensemble des packages installés, il suffit d’exécuter la fonction update.packages() :
Sous RStudio, on pourra alternativement cliquer sur Update dans l’onglet Packages du quadrant inférieur droit.
Si on souhaite désinstaller une extension précédemment installée, on peut utiliser la fonction remove.packages() : remove.packages(« gtsummary »)
Après une mise à jour majeure de R, il est souvent nécessaire de réinstaller tous les packages utilisés. De même, on peut parfois souhaiter mettre à jour uniquement les packages utilisés par un projet donné sans avoir à mettre à jour tous les autres packages présents sur son PC.
Une astuce consiste à avoir recours à la fonction renv::dependencies() qui examine le code du projet courant pour identifier les packages utilisés, puis à passer cette liste de packages à remotes::install_cran() qui installera les packages manquants ou pour lesquels une mise à jour est disponible.
Il vous suffit d’exécuter la commande ci-dessous :
renv::dependencies()
purrr::pluck(« Package »)
remotes::install_cran()
Sélection et indexation d’observations
Comme vous l’avez déjà sans doute remarqué dans les différents codes que nous avons exécutés jusqu’ici, pour accéder à une variable contenue dans un data frame, on utilise son nom préfixé du symbole $ et du nom du data frame. head(hote$age) permet affiche l’âge des six premiers individus dans la base.
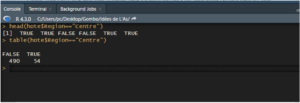
Considérons la variable Région qui indique la région d’origine des répondants. Si l’on ne s’intéresse qu’aux individus venant de la région du centre, on peut utiliser un filtre logique avec l’opérateur == (égalité logique) pour sélectionner les observations remplissant cette condition. On pourra dresser un tableau d’éffectifs en utilisant le même principe via table().
head(hote$Region== »Centre »)
table(hote$Region== »Centre »)
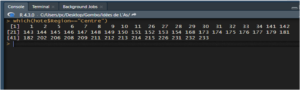
La commande which() permet de renvoyer les numéros d’observations (lignes du tableau) remplissant une condition :
On rappelle que la condition peut être formulée avec les opérateurs mathématiques classiques dont les représentations sous R sont les suivantes :
==(égalité), !=(non égalité), ! (négation), &(et),|(ou), >(supérieur à), >=(supérieur ou égal à), <(inférieur à), <=(inférieur ou égal à).
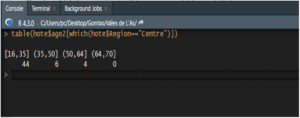
On peut aussi tabuler les groupes d’âge (age2) des personnes venant de la région du Centre :
table(hote$age2[which(hote$Region== »Centre »)])
Toutefois, R offre une commande plus intéressante qui permet de sélectionner à la fois des observations remplissant une ou plusieurs conditions, et un sous-ensemble de variables. Il s’agit de la commande subset() qui prend comme premier argument le nom du data frame sur lequel on souhaite opérer, comme deuxième argument un ou plusieurs filtres logiques à appliquer aux lignes, et comme troisième argument le numéro ou le nom des variables à sélectionner.
subset(hote, hote$Region== »Centre », c(Sexe, age, instruction ))
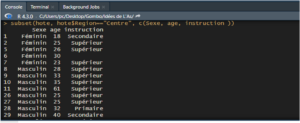
Tableau de fréquences relatives
Le tableau d’éffectifs pour la variable age2 peut être stocké directement dans une variable auxiliaire, tab.
tab=table(hote$age2)
Il existe une commande dont le rôle est de fournir les fréquences relatives, prop.table(), et qui se révélera beaucoup plus utile dans le cas des tableaux à deux entrées.
prop.table(tab)
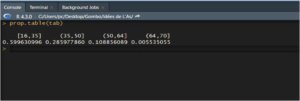
Notons également qu’il est possible de limiter l’affichage des décimales à l’aide de round(), en précisant le nombre de décimales à afficher en deuxième argument : round(prop.table(tab), 2)
Si au lieu des fréquences relatives on souhaite afficher des pourcentages, on multipliera simplement les fréquences relatives renvoyées par prop.table() par 100 :
round(prop.table(tab)*100, 2)
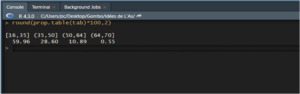
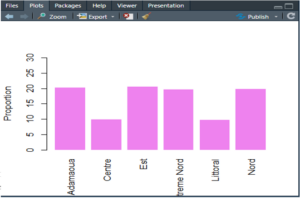
Diagramme en barres
Le panneau de visualisation des graphiques dispose d’un outil d’historique qui permet de naviguer entre les différents graphiques générés, et d’une fonction d’exportation des graphiques au format PDF ou PNG.
La commande barplot() permet de construire des diagrammes en barres (encore appelés diagrammes en bâtons) pour résumer la distribution d’effectifs observée pour une variable catégorielle à k modalités. On fournit à cette commande non pas une variable mais directement un tableau d’effectifs ou de fréquences construit avec table(). Les principaux paramètres graphiques permettant de personnaliser le rendu final de la figure ci-dessous représentant la distribution de la région d’origine de la population hôte sont illustrés dans l’instruction suivante.

Il est tout à fait possible d’utiliser un diagramme en points dotplot(), en utilisant à peu près la même syntaxe que celle présentée ci-dessus.
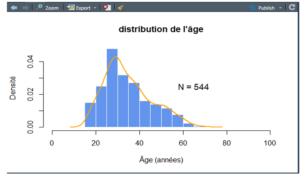
Histogramme
La commande hist() permet de représenter la distribution d’une variable numérique (continue ou discrète) sous forme d’effectif ou de densité. Le nombre de classes, ainsi que la largeur des intervalles de classe, peuvent être paramétrés à l’aide des options nclass= et breaks=. La figure suivante montre une application de cette commande pour la variable age. Notons qu’une courbe de densité a été ajoutée à l’histogramme. Pour cela, on utilise la commande lines() qui permet de travailler sur la même fenêtre graphique et superposer plusieurs éléments graphiques. Le nombre total d’observations a été également ajouté au graphique, à l’aide depaste()qui permet de juxtaposer du texte libre et, par exemple, des expressions R.